Hitaya — Informatica Data Engineering Hackathon 2024
Introduction
Hitaya is a one-stop solution for medical diagnosis-based software applications that allows users to upload medical data/records/reports such as X-ray scans, and the app will predict whether a patient has any disease or not. Our app has a dedicated dashboard which shows patient summaries, with evident data analysis and visualization over several parameters. Educates about the disease parameters from medical facts, which are constantly updated with the latest information.

Machine Learning and Data Engineering have been revolutionizing, specifically in healthcare. Data engineering along with ML models can now detect patterns underlying diseases. In this way, AI techniques can be considered as the second pair of eyes for doctors, that can decode patient health knowledge extracted from large data sets by summing up facts & observations of diseases. It can be termed a Copilot for doctors and medical institutions to speed up disease detection by showing real-time analysis and recommending basic cures and diet plans. Our models have been made using historical data from trusted healthcare boards for research and development purposes.
Problem Statement
Healthcare and medical data is critical as it contains patient’s vital information. Such large amounts of data, when collected over a long period can be unstructured, varying across metrics, and unprocessed and hence need to be analyzed well before predictive modelling to bring out insights and make informed decisions.
Solution Overview
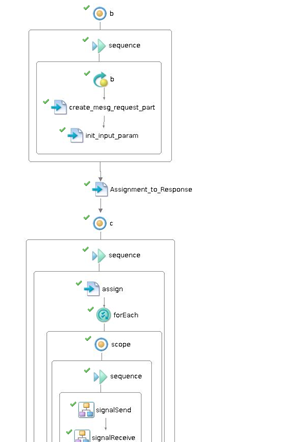
Here is a sample workflow diagram of our application. This shows how our backend and front end are connected leveraging IDMC services.

Informatica is the go-to tool for handling such huge amounts of data from source to target by making all forms of transformations necessary for a particular use case. Informatica IDMC's (Intelligent Data Management Cloud) cloud-native solution makes it easier for developers to manage vast quantities of data transformations within seconds. Data can be brought from any source, of any type, to serve any user anywhere. IDMC provides enormous data input options from where we can retrieve data using mass ingestion and start processing with data integration, data profiling, and data quality checks to name a few!
These features allow setting rules and provide data governance and privacy, a cloud-first, microservices-based, API-driven platform that’s both elastic and serverless.

CLAIRE, AI Engine technology for intelligent automation, is embedded in every service. With CLAIRE’s AI copilot capabilities, we can automate data management tasks by scheduling pipelines while reducing complexity, enabling scale and speeding up data delivery.
Creating a machine learning (ML) pipeline for training disease diagnosis data from Snowflake using Informatica INFACore involves several steps. Here’s a high-level overview of the process:
● Data Collection: Open Source and readily available data is collected from various sources. This primarily contains patients’ historical data on a large scale of factors influencing a particular disease. The data is saved into CSV as Flat files and ingested to Informatica Mass Ingestion.
● Data Processing: Clean and preprocess the data using Informatica, Data Profiling, and Data Quality checks. This may involve normalizing data, handling missing values, and creating features that will be used for training the ML model.
● Data Loading: Load the processed data into Snowflake tables using Data Integration. Ensure that the data is stored in an organized manner that’s conducive to analysis and model training.
● Model Training: Utilize Informatica INFACore to read, write and use frequently available functions over pandas data frames for model training. Made use of popular ML frameworks like sci-kit-learn, XGBoost, and LightGBM for training.
● Model Deployment: After training, deploy your model using ModelServe. This includes managing models with Model Registry, which allows secure deployment and management of models in Informatica.
● Model Inference: Leverage the deployed model through ModelServe Deployment RestAPI. This can be done by setting up a pipeline that automatically feeds new data to the model and retrieves predictions.
● Monitoring and Management: Continuously monitor the performance of your ML model and manage its privileges. This includes updating the model with new data and retraining if necessary.
Technical Details
Mass Ingestion
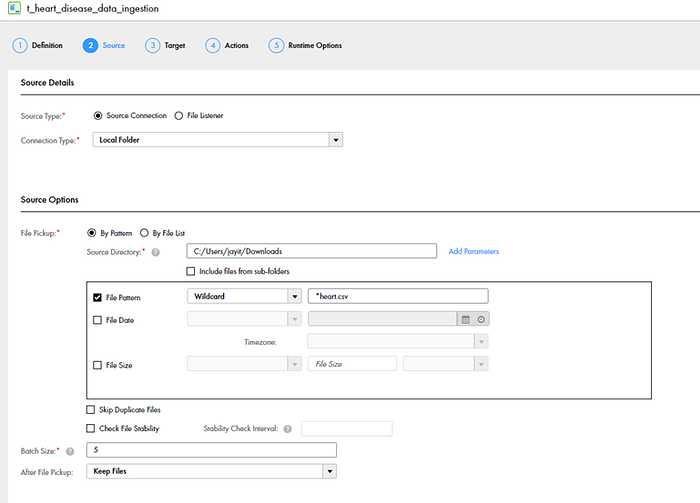
Mass ingestion involves the systematic transfer and replication of substantial volumes of data, typically between different databases or repositories, to facilitate their utilisation or storage. To efficiently manage the ingestion or replication of extensive data sets between a relational database and a Hive or HDFS target.
We’ve our dataset into the form of CSV files data which we load into the respective snowflake tables using flat file mass ingestion. This is configured by setting the source connection to the local directory of our target dataset. The target connection configuration indicates the destination where the dataset will be finally loaded through mass ingestion and a snowflake object is being configured as the target destination.
Data quality
Data quality maintains the accuracy, completeness, consistency, and reliability of data stored in sources and used for training AI Models. The data from the source dataset is applied through a set of predefined and custom rule sets to enhance the quality of the desired data.
The above snapshot shows how it can cleanse the input data and produce the expected results. We have standardized our data further using the dictionary where we specified the valid values of the diagnosis column to M and B and whenever this column receives the data other than that it will simply standardize the data to the value set to the output column.
Data Profiling
Data Profiling assesses the quality of data based on our requirements. Analysing data to understand its content, structure and patterns. Identify anomalies, inconsistencies, and potential issues in the data.
Content Assessment: Data profiling examined value frequencies, data types, and distribution. It helped us to understand what data exists, how often it occurs, and whether it aligns with our expectations.
Structure Assessment: Data profiling identifies keys, functional dependencies, and relationships between data elements. It ensures that data adheres to expected structures (e.g., primary keys, foreign keys).
Data Integration
At Data Integration we have combined data from different sources and streamlined it to upload to Snowflake Data Warehouse.
- Joiner: joined data from different sources.
- Filter: Filter data from the sequence flow.
- Expressions: Performed calculations on individual rows of data.
- Aggregator: Performed aggregate on our data.
- Normalizer: normalised the data.
InfaCore
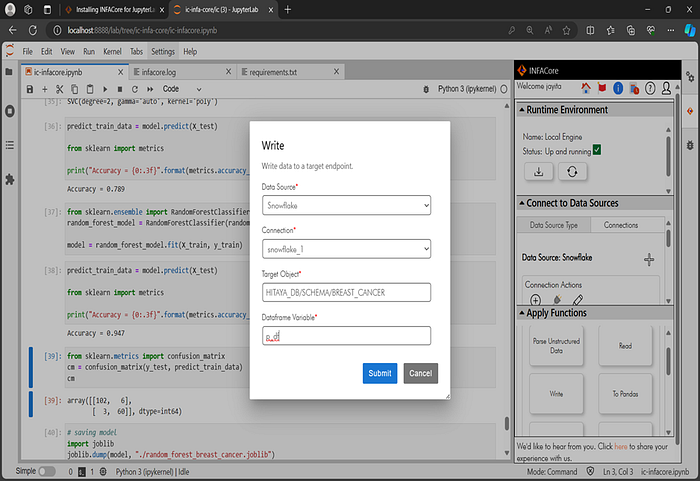
INFACore accesses data from diverse data sources, explores data, applies functions, transforms the data, and delivers quality data to your business. We’ve leveraged INFACore SDK for Python and JupyterLab extension for INFACore tools to build machine learning models for different types of disease predictions by injecting data from flat files and saving transformations/predictions to the target Snowflake database warehouse.
Model Serve
The trained model from InfaCore can be registered using Model Registry and a zip file containing prediction files, and packages to make use of while inferencing to test out model performance and integrate with Rest endpoints into existing applications.
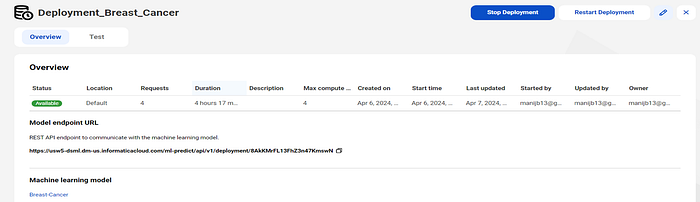
Simplifying MLOps with Informatica ModelServe. Model Serve to deploy machine learning models and generate predictions based on historical data. Monitor, alert and consume served AI/ML models in applications.
Application Integration

React App is calling Application Integration published API, to get the diet plans.
- Service Connector using Form: Connect to OpenAI Rest endpoint, sending age, weight health condition and prompt template to fetch the ChatGPT response with a Day wise Diet plan.
- App Connection: perform actions to connect our process to a service connector.
Snowflake
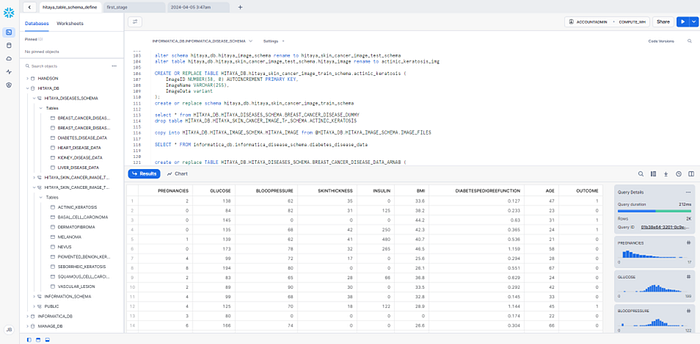
IDMC provides a Snowflake cloud Connector, which allows us to integrate Snowflake with IDMC workflows. We used this connector to extract, transform, and load (ETL) data IDMC to load source data from databases, applications, and data files in the cloud or on-premises into Snowflake.
We’ve configured a snowflake connection to our IDMC data platform by specifying the account Name, credentials, warehouse and runtime environment. Then we created a mapping to read comma-delimited files locally and write the results into the respective tables in Snowflake. This dataset for diabetes predictions is now loaded to its respective table in Snowflake.
Implementation Challenges
Building a machine-learning disease prediction application from diverse data sources with unstructured and unprocessed data presents numerous challenges. Data heterogeneity and inconsistency across sources require extensive preprocessing to standardize formats, handle missing values, and remove noise. Identifying relevant features amidst unstructured data demands sophisticated techniques, potentially necessitating domain expertise. Furthermore, ensuring data quality and reliability poses a challenge, as unclean data can lead to biased or inaccurate predictions. Integration of disparate data sources while maintaining data integrity and privacy adds complexity. Finally, scalability and computational resource requirements for processing large volumes of unstructured data are significant considerations. Addressing these challenges demands robust data preprocessing, feature extraction, quality assurance, and scalable machine learning algorithms.

Informatica Intelligent Data Management Cloud (IDMC) offers several features that can help overcome challenges in building a disease prediction machine learning application. IDMC provides a unified platform for data integration, enabling seamless integration of disparate data sources. Its data quality capabilities ensure clean and reliable data for accurate predictions. With built-in governance and compliance features, IDMC helps address regulatory requirements, ensuring data privacy and security. Additionally, IDMC’s scalability and automation capabilities streamline deployment and maintenance processes, facilitating continuous monitoring and updates. Overall, IDMC empowers to efficiently manage data lifecycle, mitigating challenges related to data integration, quality, governance, and deployment in disease prediction applications.
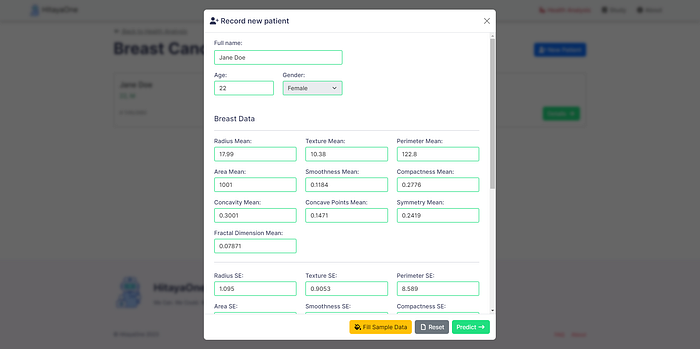
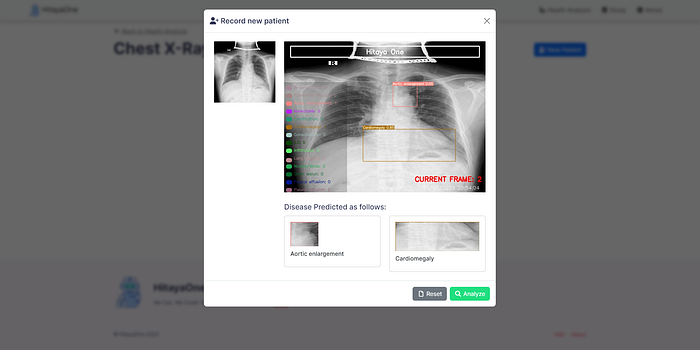
Prototype Demo:
Here is a working video demonstration of our application along with some screenshots.