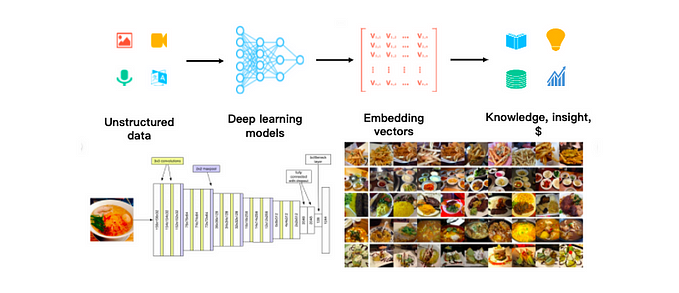
Building a RAG Chatbot using Llamaindex, Groq with Llama3 & Chainlit

What is RAG?
Retrieval Augmented Generation (RAG) is a language model that combines the strengths of retrieval-based and generation-based approaches to generate high-quality text. Here’s a breakdown of how it works:
Retrieval-based approach: In traditional retrieval-based models, the model retrieves a set of relevant documents or passages from a large corpus and uses them to generate the final output. This approach is effective for tasks like question answering, where the model can retrieve relevant passages and use them to create the answer.
Generation-based approach: On the other hand, generation-based models generate text from scratch, using a language model to predict the next word or token in the sequence. This approach is effective for tasks like text summarization, where the model can generate a concise summary of a long piece of text.
Retrieval-Augmented Generation (RAG): RAG combines the strengths of both approaches by using a retrieval-based model to retrieve relevant documents or passages, and then using a generation-based model to generate the final output. The retrieved documents serve as a starting point for the generation process, providing the model with a solid foundation for developing high-quality text.
Here’s how RAG works:
- Retrieval: The model retrieves a set of relevant documents or passages from a large corpus, using techniques like nearest neighbour search or dense retrieval.
- Encoding: The retrieved documents are encoded using a neural network, generating a set of dense vectors that capture the semantic meaning of each document.
- Generation: The encoded documents are used as input to a generation-based model, which generates the final output text. The generation model can be a traditional language model, a sequence-to-sequence model, or a transformer-based model.
- Post-processing: The generated text may undergo post-processing, such as editing or refinement, to further improve its quality.
RAG has several advantages over traditional retrieval-based and generation-based approaches:
- Improved accuracy: RAG combines the strengths of both approaches, allowing it to generate high-quality text that is both accurate and informative.
- Flexibility: RAG can be used for a wide range of NLP tasks, including text summarization, question answering, and text generation.
- Scalability: RAG can handle large volumes of data and scale to meet the demands of large-scale NLP applications.
Applications of RAG:
- Question Answering: RAG can be used to answer complex questions by retrieving relevant documents and generating accurate answers.
- Text Summarization: RAG can be used to summarize long documents by retrieving key points and generating a concise summary.
- Text Generation: RAG can be used to generate high-quality text on a given topic or prompt by retrieving relevant documents and generating coherent text.
- Chatbots and Conversational AI: RAG can be used to power chatbots and conversational AI systems that can engage in natural-sounding conversations.
To sum up RAG allows LLMs to work on your custom input data.
Benefits of Llamaindex usage in RAG
Loading Data:
Llamaindex uses “connectors” to ingest data from various sources like text files, PDFs, websites, databases, or APIs into “Documents”. Documents are then split into smaller “Nodes” which represent chunks of the original data.
Indexing Data
Llamaindex generates “vector embeddings” for the Nodes, which are numerical representations of the text. These embeddings are stored in a specialized “vector store” database optimized for fast retrieval. Popular vector databases used with LlamaIndex include Weaviate and Elasticsearch.
Querying
When a user submits a query, Llamaindex converts it into an embedding and uses a “retriever” to efficiently find the most relevant Nodes from the index. Retrievers define the strategy for retrieving relevant context, while “routers” determine which retriever to use. “Node postprocessors” can apply transformations, filtering or re-ranking to the retrieved Nodes. Finally, a “response synthesizer” generates the final answer by passing the user query and retrieved Nodes to an LLM.
Advanced Methods
Llamaindex supports advanced RAG techniques to optimize performance:
- Pre-retrieval optimizations like sentence window retrieval, data cleaning, and metadata addition.
- Retrieval optimizations like multi-index strategies and hybrid search.
- Post-retrieval optimizations like re-ranking retrieved Nodes.
By leveraging Llamaindex, you can build production-ready RAG pipelines that combine the knowledge of large language models with real-time access to relevant data. The framework provides abstractions for each stage of the RAG process, making it easier to compose and customize your pipeline.
RAG Pipeline
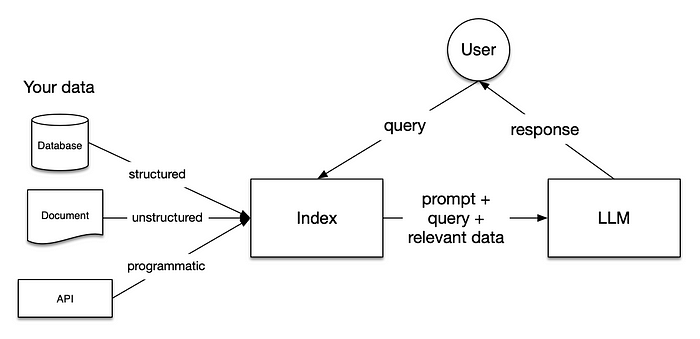
Now that we’ve got an understanding of how RAG works and how we can plug it up into Llamaindex modules, let's head onto the code implementation.
Open up IDE and start hacking! Following Python implementation needs to install the given packages below:
pip install llama-index Once installed into our Python interpreter we can import them onto Jupyter Notebook or code file:
from llama_index.core import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
ServiceContext,
load_index_from_storage
)
from llama_index.core.node_parser import SemanticSplitterNodeParser
from llama_index.embeddings.gemini import GeminiEmbedding
from llama_index.llms.groq import GroqData Ingestion
The first step in this RAG pipeline would be to load data. This could be of any format such as PDF, text, code or markdown files, SQL DB, whichever we wish to plug in.
Llamaindex offers a range of data loaders. Be it a local file store or an external one such as Google Drive or MongoDb store Llamaindex has got everything covered.
reader = SimpleDirectoryReader(input_dir="path/to/directory")
documents = reader.load_data()SimpleDirectoryReader module allows cross-format files/folders to load from the local system.
Parameters:
input_dir — defines the local directory path which contains files to load. To read from subdirectories set recursive=True.
input_files — defines a list of files that will be included to load.
SimpleDirectoryReader(input_files=["path/to/file1", "path/to/file2"])exclude — defines a list of files that will excluded from the directory.
SimpleDirectoryReader(
input_dir="path/to/directory", exclude=["path/to/file1", "path/to/file2"]
)required_exts — defines a list of file format extensions to include from a given directory.
SimpleDirectoryReader(
input_dir="path/to/directory", required_exts=[".pdf", ".docx"]
)show_progress=True shows the number of files being processed in the sequence of runs.
for multiprocessing:
documents = reader.load_data(num_workers=4)For detailed information on more capabilities refer to the below documentation:
Vector Embeddings
An embedding is a mathematical mapping that transforms raw data into a numerical representation, called a vector, that captures the essential features and relationships of the data. This vector representation, also known as an embedding vector, is a compact and expressive way to represent complex data in a lower-dimensional space.
Word embeddings: Represent words as vectors in a high-dimensional space, capturing their semantic meaning and relationships. Examples include Word2Vec and GloVe.

Properties of embeddings:
- Distributed representation: Embeddings represent data as dense vectors in a high-dimensional space, allowing for efficient computation and comparison.
- Semantic meaning: Embeddings capture the semantic meaning and relationships between data points, enabling tasks like clustering, classification, and retrieval.
- Low-dimensional representation: Embeddings reduce the dimensionality of the data, making it easier to process and analyze.
- Robustness to noise: Embeddings can be robust to noise and variations in the data, enabling more accurate predictions and decisions.
Llamaindex offers a bundle of embedding model options ranging from both open & closed-source models.
pip install llama-index-embeddings-huggingface llama-index-embeddings-geminifrom llama_index.embeddings.huggingface import HuggingFaceEmbedding
embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5"
)pip install google-generativeai>=0.3.0 llama-index-embeddings-geminifrom llama_index.embeddings.gemini import GeminiEmbedding
embed_model = GeminiEmbedding(model_name="models/embedding-001")For this particular RAG pipeline, we’ve made use of Google Gemini Embeddings having an embedding dimension of 768. Acquire the API key from Google Makersuite, wherein we can sign in using our Google account and create a new key.
model_namedefaults to 'models/embedding-001'
Chunking
Chunking is a cognitive process that involves breaking down information into smaller, more manageable units, called “chunks,” to facilitate learning, memory, and retrieval. This process is essential for efficient information processing, as it helps to reduce cognitive overload and improve comprehension.

Types of chunking:
- Character Splitting — Simple static character chunks of data
- Recursive Character Text Splitting — Recursive chunking based on a list of separators
- Document Specific Splitting — Various chunking methods for different document types (PDF, Python, Markdown)
- Semantic Splitting — Embedding walk-based chunking
splitter = SemanticSplitterNodeParser(
buffer_size=1,
breakpoint_percentile_threshold=95,
embed_model=embed_model
)
nodes = splitter.get_nodes_from_documents(documents, show_progress=True)Instead of chunking text with a fixed chunk size, the semantic splitter adaptively picks the breakpoint in between sentences using embedding similarity. This ensures that a “chunk” contains sentences that are semantically related to each other.
Transformations & Ingestion Pipeline
After the data is loaded, you then need to process and transform your data before putting it into a storage system. These transformations include chunking, extracting metadata, and embedding each chunk. This is necessary to make sure that the data can be retrieved and used optimally by the LLM.
Transformation input/outputs are Node objects (a Document is a subclass of a Node). Transformations can also be stacked and reordered.
from llama_index.core import Document
from llama_index.embeddings.gemini import GeminiEmbedding
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.extractors import TitleExtractor
from llama_index.core.ingestion import IngestionPipeline, IngestionCache
# create the pipeline with transformations
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0),
TitleExtractor(),
GeminiEmbedding(),
]
)
# run the pipeline
nodes = pipeline.run(documents=[Document.example()])An IngestionPipeline uses a concept Transformations that is applied to input data. These Transformations are applied to input data, and the resulting nodes are either returned or inserted into a vector database (if given). Each node+transformation pair is cached so that subsequent runs (if the cache is persisted) with the same node+transformation combination can use the cached result and save you time.
Settings
The Llamaindex Settings module helps in configuring global settings that can be used throughout the pipeline. Earlier the same could be achieved via ServiceContext.
from llama_index.llms.groq import Groq
from llama_index.embeddings.gemini import GeminiEmbedding
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core import Settings
Settings.llm = Groq(model="llama3-70b-8192")
Settings.embed_model = GeminiEmbedding(model_name="models/embedding-001")
Settings.text_splitter = SentenceSplitter(chunk_size=1024)
Settings.chunk_size = 512
Settings.chunk_overlap = 20
Settings.transformations = [SentenceSplitter(chunk_size=1024)]
# maximum input size to the LLM
Settings.context_window = 4096
# number of tokens reserved for text generation.
Settings.num_output = 256Vector Store Index
After the data is loaded, chunked and embedded its time to now store it in a vector database. For this example, we’re going to make use of LlamaIndex in-memory db called vector store index. This will create a bunch of JSON files with vector embedding chunks once persisted from primary to secondary memory storage using the StorageContext module.

Vector stores accept a list of Node objects and build an index from them.
vector_index = VectorStoreIndex.from_documents(
documents, show_progress=True,
service_context=service_context,
node_parser=nodes
)
vector_index.storage_context.persist(persist_dir="./storage")
storage_context = StorageContext.from_defaults(persist_dir="./storage")
index = load_index_from_storage(
storage_context,
service_context=service_context
)After the storage is created & persisted we can make use of it in future calls, with the load_index_from_storage() method which accepts the service context object and storage_context object.
Open-Source LLMs with Groq
Groq LPU (Language Processing Engine) has been revolutionizing the Open Source LLM space. It has a deterministic, single-core streaming architecture that sets the standard for GenAI inference speed with predictable and repeatable performance for any given workload.
pip install llama-index-llms-groq
llm = Groq(model="llama3-70b-8192", api_key=GROQ_API_KEY)GroqCloud API makes it at any developer’s fingertips to easily plug into the LLMs without hosting locally, directly getting the powerhouse with the least latency rates recorded to date!
Signup/log in to GroqCloud an account and get started by creating an API key at https://console.groq.com/keys.
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pre-trained and instruction-tuned generative text models in 8 and 70B sizes. The Llama 3 instruction-tuned models are optimized for dialogue use cases and outperform many available open-source chat models on common industry benchmarks.
Query/Chat Engine
The above-created index variable can now be referenced to query over user questions and build a QnA system using the as_query_engine() method. The same can be turned into a chatbot having context and chat history for the session using the chat_engine = as_chat_engine() function with the same set of parameters and would change to chat_engine.chat(query). This we will see in the next segment while building the final chatbot.
query_engine = index.as_query_engine(
service_context=service_context,
similarity_top_k=10,
)
query = "What is difference between double top and double bottom pattern?"
resp = query_engine.query(query)
print(resp.response)A double top pattern is a bearish technical reversal pattern that forms after an asset reaches a high price twice with a moderate decline between the two highs, and is confirmed when the asset's price falls below a support level equal to the low between the two prior highs. On the other hand, a double bottom pattern is a bullish reversal pattern that occurs at the bottom of a downtrend, signaling that the sellers are losing momentum and resembles the letter “W” due to the two-touched low and a change in the trend direction from a downtrend to an uptrend. In summary, the key difference lies in the direction of the trend change and the shape of the pattern.The above answer is from the document fed “All Chart Patterns.pdf” file which has the context of different stock market-related candlestick charts to showcase.
Chainlit

Now that our RAG pipeline is built, we can serve it as a SaaS model to end customers with the help of a chatbot. To build this, we’ll use the Chainlit library which is built on top of Streamlit, the popular Python app to showcase quick Data Science and ML demos. Chainlit has a UI similar to that of ChatGPT.
from llama_index.core import StorageContext, ServiceContext, load_index_from_storage
from llama_index.core.callbacks.base import CallbackManager
from llama_index.embeddings.gemini import GeminiEmbedding
from llama_index.llms.groq import Groq
import os
from dotenv import load_dotenv
load_dotenv()
import chainlit as cl
GOOGLE_API_KEY = os.getenv("GEMINI_API_KEY")
GROQ_API_KEY = os.getenv("GROQ_API_KEY")
@cl.on_chat_start
async def factory():
storage_context = StorageContext.from_defaults(persist_dir="./storage")
embed_model = GeminiEmbedding(
model_name="models/embedding-001", api_key=GOOGLE_API_KEY
)
llm = Groq(model="llama3-70b-8192", api_key=GROQ_API_KEY)
service_context = ServiceContext.from_defaults(
embed_model=embed_model, llm=llm,
callback_manager=
CallbackManager([cl.LlamaIndexCallbackHandler()]),
)
index = load_index_from_storage(
storage_context,
service_context=service_context
)
chat_engine = index.as_chat_engine(
service_context=service_context,
similarity_top_k=10
)
cl.user_session.set("chat_engine", chat_engine)
@cl.on_message
async def main(message: cl.Message):
chat_engine = cl.user_session.get("chat_engine")
response = await cl.make_async(chat_engine.query)(message.content)
response_message = cl.Message(content="")
for token in response.response:
await response_message.stream_token(token=token)
await response_message.send()“pip install chainlit” to create the above file. There is a default config.toml file (found under .chainlit folder) along with the application which serves the Readme for the app, can be configured to give custom HTML, CSS, and JS codes to make changes to the look and feel of the app along with other app-related settings like telemetry.
To run the above code from the terminal save it into the app.py file and run the command “chainlit run app.py”.
Refer to official docs: https://docs.chainlit.io/integrations/llama-index
Conclusion
For the entire code implementation refer to the following Github repo:
Click on the given link for the updated Colab notebook.